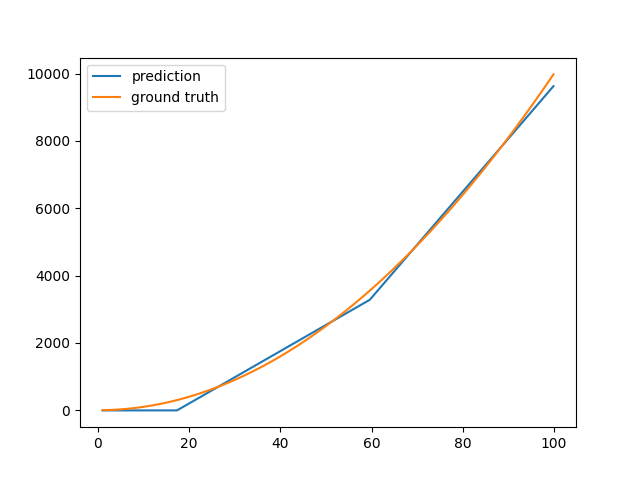
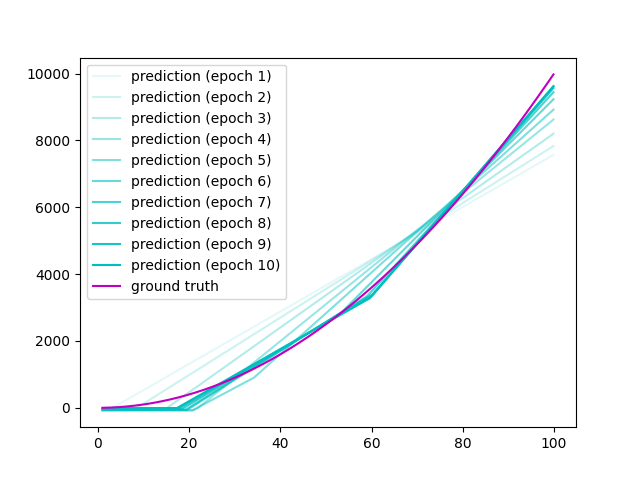
[initial] a1: 7.645e-01, a2: 8.300e-01, a3: -2.343e-01, b1: 9.186e-01, b2: -2.191e-01, b3: 2.018e-01, a4: -2.811e-01, a5: 3.391e-01, a6: 5.090e-01, b4: -4.236e-01,
[epoch 1] a1: 6.548e+00, a2: 6.514e+00, a3: -2.343e-01, b1: -1.892e+01, b2: -1.985e+01, b3: 2.018e-01, a4: 5.892e+00, a5: 6.098e+00, a6: 5.090e-01, b4: -1.928e+01,
[epoch 2] a1: 5.810e+00, a2: 5.777e+00, a3: -2.343e-01, b1: -4.590e+01, b2: -4.686e+01, b3: 2.018e-01, a4: 7.261e+00, a5: 7.543e+00, a6: 5.090e-01, b4: -4.541e+01,
[epoch 3] a1: 4.803e+00, a2: 4.763e+00, a3: -2.343e-01, b1: -6.887e+01, b2: -6.988e+01, b3: 2.018e-01, a4: 9.934e+00, a5: 1.032e+01, a6: 5.090e-01, b4: -6.634e+01,
[epoch 4] a1: 4.096e+00, a2: 3.960e+00, a3: -2.343e-01, b1: -8.500e+01, b2: -8.641e+01, b3: 2.018e-01, a4: 1.348e+01, a5: 1.402e+01, a6: 5.090e-01, b4: -7.723e+01,
[epoch 5] a1: 4.420e+00, a2: 2.857e+00, a3: -2.343e-01, b1: -9.158e+01, b2: -9.759e+01, b3: 2.018e-01, a4: 1.631e+01, a5: 1.751e+01, a6: 5.090e-01, b4: -7.404e+01,
[epoch 6] a1: 4.848e+00, a2: 2.008e+00, a3: -2.343e-01, b1: -9.463e+01, b2: -1.073e+02, b3: 2.018e-01, a4: 1.780e+01, a5: 2.537e+01, a6: 5.090e-01, b4: -6.693e+01,
[epoch 7] a1: 4.871e+00, a2: 1.913e+00, a3: -2.343e-01, b1: -9.400e+01, b2: -1.129e+02, b3: 2.018e-01, a4: 1.753e+01, a5: 3.346e+01, a6: 5.090e-01, b4: -5.220e+01,
[epoch 8] a1: 4.958e+00, a2: 1.922e+00, a3: -2.343e-01, b1: -9.120e+01, b2: -1.157e+02, b3: 2.018e-01, a4: 1.655e+01, a5: 3.823e+01, a6: 5.090e-01, b4: -3.459e+01,
[epoch 9] a1: 5.034e+00, a2: 1.945e+00, a3: -2.343e-01, b1: -8.902e+01, b2: -1.168e+02, b3: 2.018e-01, a4: 1.577e+01, a5: 4.008e+01, a6: 5.090e-01, b4: -1.901e+01,
[epoch 10] a1: 5.066e+00, a2: 1.968e+00, a3: -2.343e-01, b1: -8.785e+01, b2: -1.172e+02, b3: 2.018e-01, a4: 1.533e+01, a5: 4.061e+01, a6: 5.090e-01, b4: -5.998e+00,